Úvod do teorie konečných
automatů a formálních jazyků.
Pavel Kocur - prosinec 2000
Deterministický
KA bez výstupu - akceptor (rozpoznávací či klasifikační automat)
Deterministický
konečný automat s výstupem
Graf
přechodů (stavový diagram)
Nedeterministický
konečný automat
Slovo, délka
řetězce, zřetězení slov
Jazyk
rozpoznatelný konečným automatem
Vztah
regulárních gramatik a konečných automatů
Přehled základních pojmů
Konečný automat (KA) je abstraktní (virtuální) systém s konečným počtem stavů, na jehož vstup přicházejí symboly vstupní abecedy a KA na jejich příchod reaguje přechodem do následujícího stavu. KA pracuje v diskrétním čase. Je možno jej považovat za abstraktní obraz konkrétního systému, který např. rozpozná řetězec patřící do nějakého formálního jazyka, či nahlásí „poruchový“ stav v případě, že sleduje sekvenci symbolů na svém vstupu a ocitne se v tzv. koncovém stavu.
Později uvedeme stručné definice jednotlivých automatů.
Teorii konečných automatů a formálních jazyků je možno chápat jako součást teorie počítačů (teorie programování, návrh překladačů programovacích jazyků, návrh a specifikace komunikačních protokolů, návrh sekvenčních obvodů počítačových systémů atd.). Teorie konečných automatů je disciplinou teoretické (matematické) informatiky.
Dále je uveden stručný přehled nejzákladnějších pojmů, které mají vztah k problematice zpracované v tomto dokumentu.
Množina je soubor prvků. Zápis množiny provádíme výčtem
prvků: {a; b, c, …} nebo zápisem
X = {x; P(x)} nebo X = {x| P(x)}, kde X je množina prvků x, které mají
vlastnost P; takových prvků, že výrok P(x) je pravdivý. Množiny zde značíme
kapitálkami, prvky verzálkami.
a je prvkem množiny A zapisujeme: a Î A;
b není prvkem množiny B zapisujeme: b Ï B.
Komplikovanější výroky lze specifikovat známým způsobem s využitím funktorů (logických spojek) a kvantifikátorů ve výrazech.
|
a Þ b |
Funktor implikace: z a plyne b; jestliže a pak b |
|
a Û b |
Funktor logické ekvivalence symbolizuje, že výrok a platí právě tehdy, když platí výrok b |
|
" |
obecný kvantifikátor (pro všechna …) |
|
$ |
existenční kvantifikátor (existuje …) |
Zápis A Í B vyjadřuje vztah mezi A a B: A je podmnožinou B. Když A Í B a zároveň $x takové, že x Î B a x Ï A, jedná se o vlastní podmnožinu. Zapisujeme A Ì B. U množin nezáleží na pořadí zapsaných prvků. V teorii konečných automatů však často používáme objekty, které se skládají z prvků a na pořadí záleží. Setkáváme se tak s pojmem uspořádané množiny. Pokud záleží na pořadí prvků hovoříme o posloupnostech. Ty zapisujeme do závorek, buď okrouhlých (a1, a2, …, an) jako v tomto dokumentu, nebo úhlových <a1, a2, …, an>. Důležitý druh posloupností, zde užívaných, jsou uspořádané dvojice, tj. posloupnosti o dvou prvcích. Prvky nějaké množiny mohou vstupovat mezi sebou, či s prvky jiných množin v jisté relace.
Kartézský součin A x B je množina všech uspořádaných dvojic (posloupností), v nichž je na prvním místě vždy prvek z množiny A a na druhém místě prvek z množiny B:
P2 = A x B = {(a,b); aÎA a bÎB }. Binární relace R je jakákoli podmnožina kartézského součinu A x B. Tedy R Ì P2 Zapisujeme aRb. Uspořádané dvojice relací splňují určitou vlastnost. A je počáteční množina, B koncová množina relace. Existuje celá řada typů relací. V teorii KA se často užívají relace na množině.
Binární relace na množině M je (x,y) Î R Ì
M x M
Tato relace je ekvivalence ~ když je reflexívní ("x Î M je
xRx) , symetrická ("[x,y]
Î
M je xRy Û
yRx) a tranzitivní ("[x,y,z)]
Î
M ze vztahů xRy a a yRz plyne xRz)
Parciální funkce je zobrazením - zvláštním druhem relace, značíme ji F: A® B; F Ì A x B a pro každé aÎA existuje nejvýše jedno bÎB takové, že (a,b) Î F. Funkce je definována tak, že pro každé aÎA existuje právě jedno bÎB takové, že (a,b) Î F
Relační struktura je matematický objekt, který popisuje
systém skládající se z částí (vrcholy) a mezi těmito částmi existují jisté
vztahy (hrany). Relační strukturu je možno chápat i jako uspořádanou dvojici,
jejíž první člen je množina vrcholů a druhý člen množina hran. V teorii
konečných automatů se setkáme s hranami unárními (tj. s hranami
s jedním vrcholem) a binárními (se dvěma vrcholy). Orientovaný ohodnocený
graf je struktura, která se skládá pouze z binárních hran. Orientovaný
graf můžeme chápat jako dvojici (V, H), kde V je množina vrcholů a H
množina hran H Í
V x V; hrana (u,v) Î H vychází
z vrcholu
u a vstupuje do vrcholu v. Někdy se orientovaný graf
definuje jako trojici (V, H, e), a e je zobrazení H ® V2 . Jedná
se o tzv. vztah incidence, který přiřazuje každé hraně h Î H
uspořádanou dvojici vrcholů.
Řetězce jsou libovolné konečné posloupnosti symbolů dané abecedy (prvků nějaké množiny symbolů). Prefix je předpona a postfix je přípona řetězce xy.
Konečné automaty (KA) lze dělit podle různých hledisek na konečné automaty bez výstupu, konečné automaty s výstupem nebo podle jiného kriteria na konečné automaty deterministické a nedeterministické.
Deterministický KA bez výstupu - akceptor (rozpoznávací či klasifikační automat)
Deterministickým konečným automatem bez výstupu nazýváme každou
pětici
A = (Q,
Σ, δ, q0, F), kde:
Qje konečná, neprázdná, množina stavůΣje konečná neprázdná množina vstupních symbolů (vstupní abeceda)δ(přechodová funkce) je zobrazeníδ:Q´Σ®Q. Přechod je určen stavem ve kterém se automat nachází a symbolem, který přichází na vstup ( nebo který je čten na vstupu)q0je počáteční (iniciální) stav (q0ÎQ)Fje množina koncových stavů (FÍQ)
K přechodu automatu do nového stavu dochází po přečtení vstupního symbolu.
Konfigurace automatu je dvojice (q, w) Î Q x S* Přitom q je stav, ve kterém se automat právě nachází a w zbylá část řetězce, kterou automat dosud nepřečetl. Počáteční konfigurace je (q0, u). (q, e) je koncová konfigurace v případě, že q Î F. Pojem S* je vysvětlen podrobněji v části Slovo, délka řetězce, zřetězení slov
Relaci aM Ì (Q x S*) x (Q x S*) na množině konfigurací, nazýváme přechodem automatu M:
(q, aw)
aM
(p,
w), pokud δ(q, a)=p
pozn.: u klasifikačního automatu
je množina koncových stavů tvořena rozkladem množiny Q na třídy
{Qi} -
rozklad množiny stavů; rozděluje množinu řetězců ( viz. níže ) do tříd Q1,
Q2, ....., Qn :
1. Q1È Q2È .....È Qn = Q
2. QiÇ Qj, = Æ (prázdná množina), " i¹j i,j = 1,2, … , n
Konečný automat můžeme chápat též jako konečný orientovaný graf - viz dále
KA je možno využít jako analyzátor regulárních jazyků.
Deterministický konečný automat s výstupem
Deterministickým konečným automatem s výstupem nazýváme každou pětici
A = (Q,
Σ, O, δ, l)kde:
Qje konečná, neprázdná, množina stavůΣje konečná neprázdná množina vstupních prvků - symbolů (vstupní abeceda)Oje konečná neprázdná množina výstupních symbolů (výstupní abeceda)δ(přechodová funkce) je zobrazeníδ:Q´Σ®Q. Přechod je opět určen stavem ve kterém se automat nachází a symbolem, který je čten na vstupul(výstupní funkce) je zobrazeníQ´Σ®O(Mealy)neboQ®O(Moore)
Na
posloupnost vstupních symbolů reaguje KA s výstupem posloupností symbolů
výstupní abecedy. Výstupní funkci Mooreova automatu se někdy říká značkovací
funkce a označuje se místo l symbolem
μ.
U Mooreova
automatu je výstupní symbol určen pouze stavem, u Mealyho automatu pak stavem a
vstupním symbolem. Maelyho automat je obecnějším prostředkem než Moorův.
Ve stavovém diagramu zapisujeme u
příslušné hrany, která charakterizuje možný přechod, dvojici symbolů oddělených
lomítkem: a / a, kde a označuje vstupní symbol
přicházející na vstup automatu a a označuje výstupní symbol, který se objeví na
výstupu.
Př.: Mealyho automat
M = (Q, Σ, O, δ, l); Q = {1, 2, 3},
Σ
= {a1, a2},r, u, w
Q = {}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Př.: Moorův automat:
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Př.: RS klopný obvod je realizací specielního případu Mooreova automatu, kdy se stav kryje s výstupem (x/y; x značí stav, y výstup). Popis - reprezentace automatu - viz Způsoby reprezentace KA:
|
q |
RS |
||||
|
00 |
10 |
11 |
01 |
||
|
Q |
0 |
1 |
1 |
0 |
0 |
|
1 |
1 |
1 |
1 |
0 |
|
Q označuje zároveň stav i výstup RS klopného obvodu, který je sekvenčním obvodem - realizací KA s výstupem
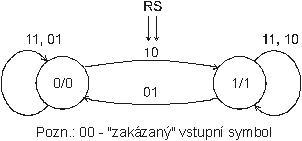
Způsoby reprezentace KA
Př.:
Mějme konečný automat M = ({q0, q1, q2, q3},
({0, 1}, d,
q0, {q0})
kde d:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabulka přechodů
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
V tabulce specifikujeme: ® vstupní stav, ¬ výstupní stav (ten je v grafu značen dvojitým kroužkem); « vstupní a zároveň výstupní stav
Graf přechodů (stavový diagram)
Konečný automat A nad S, kde S = {s1, s2, …, sn} můžeme tedy chápat i jako konečný orientovaný graf, v němž z každého uzlu vychází n hran (n je počet symbolů vstupní abecedy) a každá hrana je pojmenovaná některým symbolem si (1 £ i £ n), každá jiným. Jeden uzel (speciálně označený) je počáteční, některé uzlu mohou být koncové. Počáteční uzel může být jedním z koncových. Při specifikaci KA se hovoří o stavech (místo o uzlech).
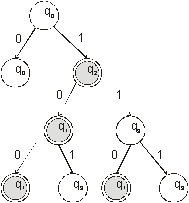
Stavový strom
Stavovým stromem lze reprezentovat pouze automaty u nichž je každý stav dosažitelný z počátečního stavu, což nevadí neboť ostatní stavy - nedosažitelné nás nezajímají. Z každého vrcholu, který není listem vychází tolik hran, kolik je symbolů vstupní abecedy. Kořen stromu je ohodnocen počátečním stavem. Ohodnocování následníků se provádí podle přechodové funkce. Koncové stavy se označují dohodnutým způsobem; počáteční stav není nutno vyznačovat. K daná tabulce je nakreslen stavový strom:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Jakákoli reprezentace automatu umožňuje zjistit reakci automatu na libovolnou posloupnost vstupních symbolů. Posloupnosti interpretujeme nejčastěji jako sled obrazů událostí probíhajících procesů. Některé události převádějí automat do koncového stavu. Jiná interpretace je chápání posloupnosti vstupních symbolů jako řetězce symbolů v jisté abecedě a automat rozpoznává které řetězce patří do daného jazyka.
V teorii konečných automatů chápeme pod pojmem orientovaný graf dvojici (V, H), kde V je konečná neprázdná množina vrcholů a H Í V ´ V (množina hran). O hraně (u,v) Î H říkáme, že vychází z vrcholu u a vchází do vrcholu v.
Stav
q konečného automatu A se nazývá dosažitelný, jestliže existuje slovo wÎS*takové,
že
d
(q0,
w) = q. Stavy které nejsou dosažitelné se nazývají
nedosažitelné.
Nedeterministický konečný automat
Nedeterministickým konečným automatem (NKA) bez výstupu
nazýváme každou pětici
A = (Q,
Σ, δ, S, F), kde:
Qje konečná, neprázdná, množina stavůΣje konečná neprázdná množina vstupních symbolů (vstupní abeceda)δ(přechodová funkce) je zobrazeníQ´(ΣÈ{e})® Ã(Q)
kde Ã(Q) je potenční množina, e - prázdný symbolSje množina počátečních stavů (SQ) - není jednoznačně určen počáteční stavFje množina koncových stavů (FÍQ)
Oborem hodnot přechodové funkce jsou všechny podmnožiny množiny stavů
Př.: Mějme konečný automat M = ({q0, q1, q2,
q3}, ({0, 1}, d, {q0}}, {q3})
kde d:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabulka přechodů
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
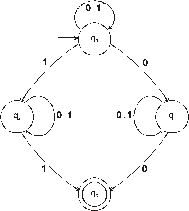
Nedeterministický konečný automat o n stavech lze převést na deterministický automat s 2n stavy. Převod nedeterministického automatu z předchozího příkladu na deterministický ukazuje následující tabulka a graf
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
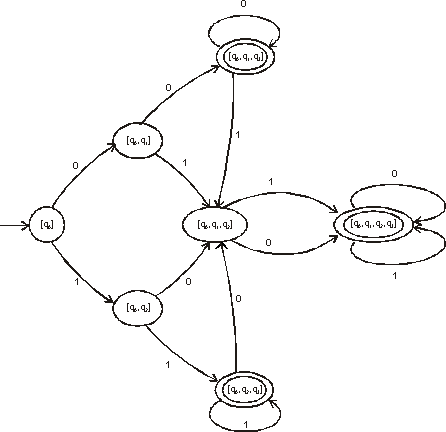
Pro vstupní řetězec 1 0 1 0 provede automat posloupnost přechodů: ([q0], 1 0 1 0) a ([q0, q2], 0 1 0) a ([q0, q1, q2], 1 0) a([q0, q1, q2, q3], 0) a([q0, q1, q2, q3], e)
Ekvivalence automatů
Dva automaty M, N jsou ekvivalentní, jestliže předepisují stejné zobrazení takové, že ke každému stavu automatu M existuje ekvivalentní stav automatu N a naopak. Definujeme tedy rozklad množiny stavů. Kterékoli dva stavy ležící ve stejné třídě jsou ekvivalentní a kterékoli dva stavy ležící v různých třídách nejsou ekvivalentní.
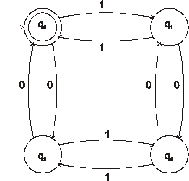
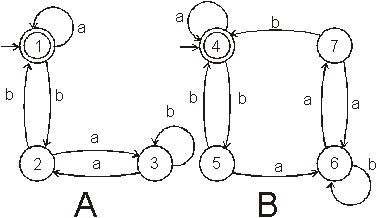
Automaty A, B nad Σ {a,b} jsou (podle
následujícího postupu) ekvivalentní
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
vA je uzel automatu A, vB je uzel automatu B;
počáteční uzly jsou označeny stínováním
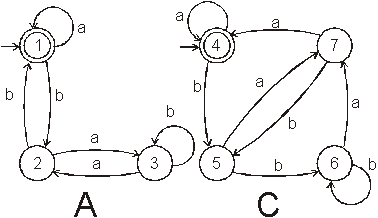
Automaty A, C z následujícího obrázku nejsou ekvivalentní, neboť uzel 1 je koncovým uzlem automatu A, avšak uzel 6 není koncovým uzlem automatu C (viz tabulka pod obrázkem)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Slovo, délka řetězce, zřetězení slov
Je-li Σ
libovolná konečná množina (abeceda), pak Σ+ označuje
množinu všech konečných neprázdných posloupností utvořených z prvků
množiny Σ
(množinu všech neprázdných řetězců); e
označuje prázdný symbol;
Definujeme
Σ*
= Σ+ È {e}
(iterace množiny Σ,
množina všech řetězců)
Posloupnost (a(1),
..., a(n)) ze Σ* budeme
zapisovat a(1),
..., a(n). Každou takovou posloupnost nazýváme slovem
v abecedě Σ; e
nazýváme prázdným slovem (též prázdný řetězec
nebo prázdný symbol).
O Σ*
mluvíme jako o množině všech slov nad abecedou Σ,
o Σ+
jako o množině všech neprázdných slov nad Σ.
Jestliže u=a(1),
..., a(n) a v=b(1), ..., b(m) Î Σ*,
pak řetězec uv=a(1), ..., a(n), b(1),
..., b(m) nazveme zřetězením řetězců (slov) u a v.
Speciálně eu = ue = u.
Symbol u^n
bude označovat n-násobné zřetězení slova u,
tzn. u^1=u, u^2=uu, u^(i+1)=u^i u.
Délku slova u budeme značit |u|, tedy |a(1), ..., a(n)| = n a
|e|=0; je
to počet symbolů v řetězci. Zřetězení řetězců je asociativní
u · v · x = u · (v · x) = (u · v) · x.
Zobecněná přechodová funkce
Přechodovou funkci δ: Q ´ Σ -> Q
konečného automatu A=(Q,Σ,δ,q0,F) rozšíříme na zobecněnou
přechodovou funkci δ*: Q x Σ* -> Q
takto:
δ*(q,e)=qpro každéqÎQδ*(q,wa)=δ(δ*(q,w),a)pro každéqÎQ, wÎΣ*aaÎΣ.
Jazykem rozpoznávaným konečným automatem A pak
nazveme jazyk L(A)
= { w ; w Î Σ* & δ*(q0,w)
Î F}.
Říkáme, že slovo w Î Σ*
je přijímáno automatem A, právě když w Î L(A).
Jazyk
Je-li Σ
konečná abeceda a L Í Σ*, pak L
nazveme jazykem nad abecedou Σ. Tato definice je
příliš obecná. Jazyk však můžeme definovat několika způsoby:
- výčtem - společnou vlastností
- automatem (akceptorem); jedná se o proces zpracování řetězce, kdy po konečném počtu kroků dojde k rozpoznání zda řetězec patří či nepatří do daného jazyka; automat řetězec akceptuje nebo ho zamítne
- generativním popisem (gramatikou); jedná se o často používanou metodu specifikace jazyka; sytém vygeneruje všechny řetězce patřící do daného jazyka
Jazyk rozpoznatelný konečným automatem
Existuje-li konečný automat A takový, že jazyk L=L(A),
říkáme, ze jazyk L je rozpoznatelný konečným
automatem.
Zavedeme li znázornění KA pomocí kroužků a šipek následovně:
Každý stav zakreslíme jedním kroužkem (v němž může být zapsáno i
jméno stavu). Každá hodnota přechodové funkce δ(q,a)=p, q,p Î Q, a
Î Σ je znázorněná šipkou ve směru
od stavu q
do stavu p
a ohodnocenou prvkem a
abecedy Σ.
Jediný počáteční stav deterministického automatu je znázorněn šipkou vedoucí
dovnitř a každý koncový stav je znázorněn dvojitým kroužkem nebo šipkou vedoucí
ven z tohoto stavu. Slovo w Î Σ*
je KA přijímáno právě tehdy, když existuje cesta z počátečního
stavu do nějakého koncového stavu ve směru šipek a posloupnost
ohodnocení šipek na této cestě je totožná se slovem w.
Množinu všech slov akceptovaných automatem A označujeme Ã. Automat
provádí čtení vstupních symbolů řetězce zleva doprava.
Jazyk rozpoznávaný (akceptovaný) konečným automatem A je
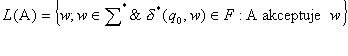
Konečný automat přijímá (akceptuje, rozpoznává) slovo w, jestliže existuje
koncový stav
p Î
F, takový, že (q0,
w) aM*
(p,
e)
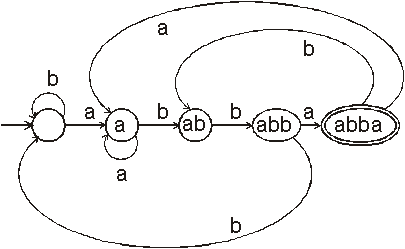
Př.: ![]() je rozpoznáván
automatem:
je rozpoznáván
automatem:
Relace ~ se nazývá pravou kongruencí (zprava invariantní), jestliže pro "
[u,v,w] Î S* ze
vztahu
u ~ v plyne uw ~ vw. O relaci ~ na množině M
říkáme, že je konečného indexu, jestliže rozklad M/~ má konečný počet tříd.
Nerodova věta
Jazyk L je rozpoznatelný konečným automatem, právě když existuje pravá
kongruence konečného indexu taková, že L je sjednocením jistých tříd rozkladu S*/~.
Regulární množiny
Třída množin slov nad S, tzv. regulárních množin nad abecedou S je definována takto:
- každá konečná množina slov nad abecedou S (včetně prázdné množiny Æ) je regulární množina
- jsou-li U a V regulárními množinami nad S, je i jejich sjednocení U È V a zřetězení U.V regulární množina nad S
- je li S regulární množinou nad S, je i S* regulární množina
- každou regulární množinu lze získat konečným počtem aplikací pravidel 1 až 3 uvedených výše.
- Regulární množiny se vhodně vyjadřují
pomocí přechodových grafů. Přechodový graf T nad S
je každý orientovaný graf, jehož každá hrana je pojmenovaná jistým slovem
w Î
S*
(tedy i prázdným); alespoň jeden uzel je označen jako počáteční a některé
(nebo žádné) jsou označeny jako koncové. Každý konečný automat je
přechodový graf. Naopak to neplatí. Přechodový graf je obecně
nedeterministický;
w cesta z uzlu i do j v přechodovém grafu T pro dané slovo w Î S* je taková cesta, když zřetězením všech jmen hran na této cestě získáme slovo w.
Regulární výrazy
Regulární výrazy umožňují algebraické manipulace s regulárními množinami - umožňují vyjádření regulárních množin.
Třída regulárních výrazů nad abecedou S je definována takto:
- e a Æ jsou regulární výrazy
- každé písmeno (symbol - znak) s
Î - jsou-li R1 a R2 regulární výrazy nad S, pak i (R1 + R2), (R1 . R2) a R1* jsou regulární výrazy nad S
Daná množina je
regulární množina nad S, právě když může být popsána vhodným regulárním výrazem
nad S.
Každý regulární výraz U popisuje jistou množinu Ũ slov nad S:
Ũ Í
S*
Regulární
množiny se vhodně charakterizují přechodovými grafy. Přechodový graf T nad
abecedou S je
konečný orientovaný graf, jehož každá hrana je pojmenována jistým slovem
w Î S* ;alespoň
jeden uzel je počáteční.
Množinu
všech slov akceptovaných konečným automatem A označíme Ã.
Množina je regulární nad S právě když je akceptována vhodným automatem
nad S
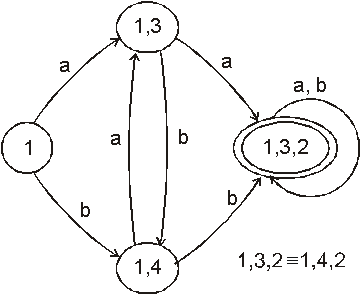
Př.: Je dán regulární výraz R =(a + b)* (aa + bb) (a + b)* . Navrhněte konečný automat, který akceptuje množinu slov popisovaných daným výrazem.
|
|
a |
b |
|
[1] |
[1,3] |
[1,4] |
|
[1,3] |
[1,3,2] |
[1,4] |
|
[1,4] |
[1,3] |
[1,4,2] |
|
[1,3,2] |
[1,3,2] |
[1,4,2] |
|
[1,4,2] |
[1,3,2] |
[1,4,2] |
Hledaný konečný automat je vyjádřen grafem:
Regulární jazyky
Každý z regulárních výrazů označuje jistý regulární jazyk. Každý regulární jazyk je rozpoznatelný konečným automatem; každý jazyk rozpoznatelný konečným automatem je regulární.
Kleenova
věta: Libovolný jazyk je regulární, právě když je rozpoznatelný konečným
automatem. Přechodový graf je T nad S je konečný
orientovaný graf, jehož každá hrana je pojmenována jistým slovem wÎS*.
Alespoň jeden z uzlů grafu je počáteční a některé uzly jsou koncové. Ke
každému přechodovému grafu T nad abecedou S existuje regulární
výraz R nad S takový,
že ![]() a ke každému
regulárnímu výrazu R nad S existuje konečný automat A takový, že
a ke každému
regulárnímu výrazu R nad S existuje konečný automat A takový, že ![]() .
.
Zásobníkový automat
Zásobníkový automat je abstraktní matematický systém. Je to jednosměrný nedeterministický automat, který má pomocnou paměť organizovanou jako zásobník.Schéma automatu je na následujícím obrázku:
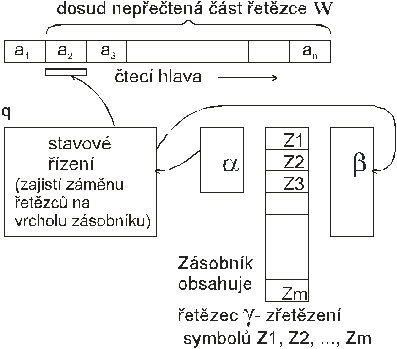
Zásobníkový automat je sedmice
Z
=
(Q, Σ, G, δ, q0,
Z0, F), kde:
- Q je konečná množina stavů
- S je konečná množina vstupních symbolů - vstupní abeceda
G- q0 je počáteční stav; q0
Î Z0ÎGje počáteční symbol v zásobníku F je množina koncových stavů; F Í
Q
F je množina koncových stavů; F Í
Q - d
- přechodová funkce je zobrazením z množiny
Q´{ΣÈ e}´GQ´G*.
Konfigurace
zásobníkového automatu je trojice (q, w, g) z množiny Q ´ S*
´
G* , kde q je současný stav, w dosud
nepřečtená část vstupního řetězce (když w = e, jsou přečteny všechny znaky), g
obsah zásobníku (když g = e, je zásobník prázdný). Počáteční konfigurace má
tvar (q0, w, Z0), koncová konfigurace
(q, e, g),
q Î
F, g
Î
G* . Podobně jako konečné automaty
umožňují tvorbu modelů pro syntaktickou analýzu regulárních jazyků, zásobníkové
automaty lze využít pro návrh analyzátorů bezkontextových jazyků.
Gramatiky
Gramatika je čtveřice: G = (N, T, S, P), kde
N je konečná množina neterminálních symbolů (ty se používají k označení syntaktických celků). Neterminální symboly se někdy nazývají metalingvistické proměnné.
T je konečná množina terminálních symbolů
přičemž N Ç
T = Æ
(Množiny N, T jsou disjunktní)
Množina terminálních symbolů je abeceda nad kterou je jazyk definován
S je počáteční symbol, S Î N označovaný též jako startovací či větný člen
P je konečná množina přepisovacích pravidel. Je to
podmnožina množiny
(N È
T)*N(N È
T) *´(N
È
T)*
Neterminální symboly označujeme velkými latinskými písmeny, terminální malými; slova z neterminálních a terminálních symbolů budeme označovat malými řeckými písmeny. Z výše uvedeného vztahu je patrné, že první člen uspořádané dvojice přepisovacího pravidla musí osahovat alespoň jeden neterminální symbol.
Když pak abg Î (N È T)*a adg Î (N È T)*, tak jsou dané řetězce v relaci derivace odvození Þ, t.j. abg Þ adg, když v P existuje přepisovací pravidlo b®d tento element někdy značíme (b,d). Jinak řečeno fakt „x přímo derivuje y“ zapisujeme x Þ y jestliže existuje přepisovací pravidlo a ® b Î P a g, d Î (N È T)* takové,že x = gab a, y = gbd
Jazyk L(G) generovaný generativní gramatikou je:
L(G) = {w; w Î S* a SÞ* w} tedy je tvořen všemi slovy v terminální abecedě, která lze odvodit z počátečního symbolu S
Klasifikace gramatik
Gramatiky klasifikujeme podle tvaru pravidel. Podle tzv. Chomského hierarchie je:
- gramatika neomezená (typu 0) když odpovídá výše uvedené definici; na tvar přepisovacích pravidel nejsou kladena žádná omezení. Jazyk generovaný touto gramatikou se nazývá jazyk typu 0
- gramatika
je kontextová (typu 1), když každé pravidlo z P má tvar a
X b
®
a
g
b;
X Î N, g Î (N È T)+ (délka řetězce |g| ³ 1). Kontextová gramatika generuje kontextový jazyk (jazyk typu 1). - gramatika
je bezkontextová (typu 2), když obsahuje pouze pravidla P typu
X ® g; X Î N, g Î (N È T)* . Bezkontextová gramatika generuje bezkontextový jazyk (jazyk typu 2). - gramatika
je regulární (typu 3), když pravidla P mají tvar
X ® wY nebo X ® w; X,Y Î N, w Î (T)* . Regulární gramatika generuje regulární jazyk (jazyk typu 3). Pro každou gramatiku typu 3 se dá sestrojit KA, který analyzuje (přijímá) stejný jazyk jaký generuje daná regulární gramatika. V uvedeném procesu vzniku KA většinou nejprve vzniká nedeterministický automat, který pak převádíme na deterministický.
Regulární jazyk jsme již reprezentovali regulárním výrazem v části „Regulární výrazy“
Př.: G = ({A,B}, {a, b}, P, A) kde P: A ® aAb | e, B ® bbA | aaB | a | B , aA ® bB | b
pozn.: znak | umožňuje stručný zápis pravidel se stejnou pravou stranou.
Vztah regulárních gramatik a konečných automatů
Je-li G = (N, T, S, P) gramatika pak
existuje A
= (Q, Σ, δ, q0, F)obecně nedeterministický
konečný automat bez výstupu, takový, že platí L(A) = L(G).
Př.: G = ({S}, {0, 1}, P, S) kde P: S ® 0S; S ® 1S, S ® 0; S ® 1
L(G) = {0, 1}+
Konečný automat M rozpoznávající jazyk generovaný výše uvedenou gramatikou specifikujeme ve tvaru: A = ({S, K}, {0, 1}, , S, {K})
kde d (S, 0) = {S, K}, d (S, 1) = {S, K}
Uvedený nedeterministický automat lze zobrazit jako:
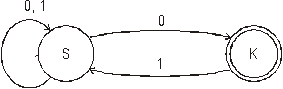
Ten lze pak převést na deterministický.
Plzeň, prosinec 2000